インターネット上にあるホームページからhtmlテキストを読み込んで、必要な情報のみ取得したいと思う時があります。プログラムで自動化できればいいのですが、結局は、コピー&ペーストを使って、手動で情報をまとめる場合が多いと思います。
C# のWPFアプリケーションで、htmlテキストを読み込み、それを正規表現を使って抽出するプログラムの基本的な部分を作成してみたいと思います。
テキストボックスに、属性を指定する
テキストボックスは、C#で使える便利コンポーネントの1つです。いろいろな機能が用意されているので、使う際に、必要な機能をどのように使用するか確認する必要があります。
テキストボックスで、多くの文字列を表示する際には、表示属性を指定すると使いやすくなります。
複数行を表示するには、改行コードの動作を変更する必要があります。
<!-- 改行を有効にする 改行コードが利用できるようになります。-->
<TextBox AcceptsReturn="True" /> テキストボックスの幅より長い文字列を扱う際には、折り返すと読みやすくなります。
<!--折り返しを有効にする 使用できる値は、折り返しを行う Wrap、折り返しを行わない NoWrap -->
<TextBox TextWrapping="Wrap" /> テキストボックスで一度に表示できないほど多くの文字列を扱う場合は、スクロールバーを表示しないと表示できなかった部分の文字列は見ることができません。
テキストボックスに、コードからテキストを挿入する
テキストボックスに、プログラムから、テキストを入力する機能を確認します。ここでは、一番基本的な、テキストボックスのテキスト全てを差し替える方法を使用します。
Name属性を与えたテキストボックスのTextプロパティに文字列を代入すると、テキストボックスに、代入した文字列が表示されます。
テキストボックスに、Name属性を追加します。
<TextBox Name="urlAdress">TextBox</TextBox>Textメソッドを使って、テキストを代入する。
htmlText.Text = "テキストをコードから入力する";テキストボックスのtextプロパティに、値を入れると、テキストボックスに表示されることがわかりました。
テキストボックスに、htmlテキストを入力する
以前、WebClientクラスのDownloadStringメソッドを使って、インターネット上のhtmlテキストを取得する方法を確認していますので、そのコードを利用して、インターネット上からhtmlテキストを取得し、テキストボックスに表示するプログラムを作成します。
C#で、WebClientクラスのDownloadStringメソッドを使用してインターネットから情報を取得する
まずは、UIを作成します。
MainWindow.xamlを以下コードを参考に変更します。一番上の行の「
x:Class="WebRegex01.MainWindow"WebRegex01<Window x:Class="WebRegex01.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:local="clr-namespace:WebRegex01"
Title="MainWindow" Height="400" Width="600">
<Grid>
<Grid.RowDefinitions>
<RowDefinition Height="*"/>
<RowDefinition Height="Auto"/>
<RowDefinition Height="*"/>
</Grid.RowDefinitions>
<DockPanel Name="targetURL" Grid.Row="0">
<DockPanel DockPanel.Dock="Top">
<Button Name="urlAcsses"
DockPanel.Dock="Right"
Width="100"
Click="urlAcsses_Click">Button</Button>
<TextBox Name="urlAdress">TextBox</TextBox>
</DockPanel>
<TextBox Name="htmlText"
AcceptsReturn="True"
VerticalScrollBarVisibility="Auto">TextBox</TextBox>
</DockPanel>
<GridSplitter Grid.Row="1" Height="2" HorizontalAlignment="Stretch" />
<DockPanel Grid.Row="2">
<DockPanel DockPanel.Dock="Top">
<Button Name="doRegex" DockPanel.Dock="Right" Width="100">Button</Button>
<TextBox Name="regexFormula">TextBox</TextBox>
</DockPanel>
<TextBox Name="regexResult" AcceptsReturn="True">TextBox</TextBox>
</DockPanel>
</Grid>
</Window>テキストボックスは、4つあります。ここでは、上の2つのテキストボックスを使用します。
ソリューションエクスプローラーで、クラスを追加します。
GetWeb.csファイルを作成します。
GetWeb.csファイルを、以下のように変更します。
以前紹介した、インターネット上からhtmlテキストを取得するプログラムを変更して、使用しています。
C#で、WebClientクラスのDownloadStringメソッドを使用してインターネットから情報を取得する
using System.IO;
using System.Net;
namespace WebRegex01
{
class GetHtmlTexte
{
// 取得したhtmlテキスト
public string result;
// コンストラクタ urlを与えると、resultにhtmlテキストを入力する
public GetHtmlTexte(string url)
{
WebClient wc = new WebClient();
try
{
using (Stream stream = wc.OpenRead(url))
using (StreamReader sr = new StreamReader(stream))
{
// Add a user agent header in case the
// requested URI contains a query.
// 要求されたURIに、問合せが含まれる場合に備えて、
// ユーザー・エージェント・ヘッダを追加します。
wc.Headers.Add("user-agent", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.0.3705;)");
string str = sr.ReadToEnd();
result = str;
}
}
catch
{
// Let the user know what went wrong.
// ユーザーに、何が問題になったのかを知らせます。
// The file could not be read:
result = "指定されたサイトを読み取れませんでした:";
}
}
}
}C#では、他の開発言語の関数のような、「パラメーターを与えて関数を呼び出すと必要な値が、返り値として得られる」という使い方ではなく、パラメーターを与えて、クラスのコンストラクタを呼び出し、その後、値が変更されたクラスメンバ変数の内容を使用するといった方法が良く使われています。
これは、今回、別のクラスファイルを作成して、その中にクラスを記述しているので、クラスを呼び出す必要があります。その際、クラスのコンストラクタが、戻り値を持つことができないからです。同じクラス内のメソッドを呼び出す場合は、戻り値を返す必要があるので、今まで意識したことがありませんでした。わかってしまえば簡単ですが、気がつくのに、かなり悩みました。 他にも方法は、ありそうなのですが、見つける事ができなかったので、それまで、この方法で、別のクラスファイルに記述されたクラスを使用することにします。
private void urlAcsses_Click(object sender, RoutedEventArgs e)
{
string url = urlAdress.Text;
GetHtmlTexte gethtml = new GetHtmlTexte(url);
htmlText.Text = gethtml.result;
}Window.xaml.csファイルを以下のように変更します。
using System.Windows;
namespace WebRegex01
{
/// <summary>
/// MainWindow.xaml の相互作用ロジック
/// </summary>
public partial class MainWindow : Window
{
public MainWindow()
{
InitializeComponent();
urlAdress.Text = "https://webdesign.vdlz.xyz/index.html";
}
private void urlAcsses_Click(object sender, RoutedEventArgs e)
{
string url = urlAdress.Text;
GetHtmlTexte gethtml = new GetHtmlTexte(url);
htmlText.Text = gethtml.result;
}
}
}ボタンを押すと、一番上のテキストボックスにあるurlのhtmlテキストを取得します。
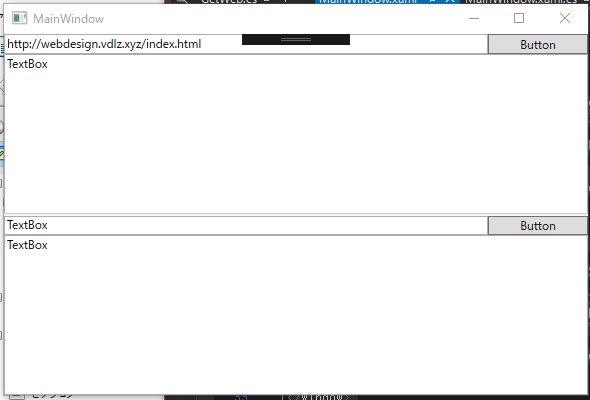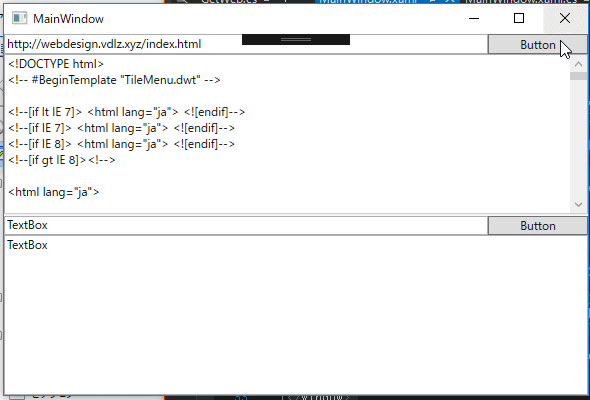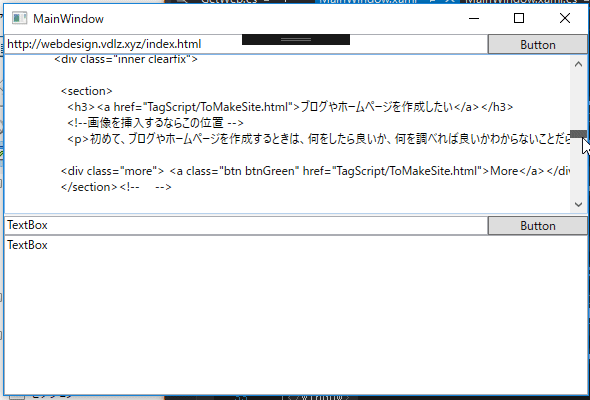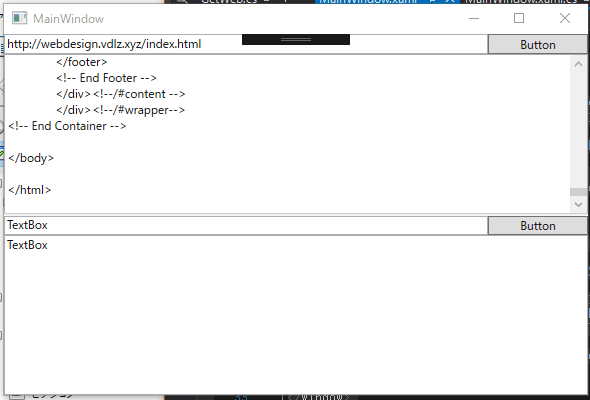
正規表現を使って必要な情報を取得する
続いて、取得したhtmlテキストから、必要な情報を抽出したいと思います。
Matchメソッド,NextMatch()メソッド:指定したパターンに一致する部分文字列を見つける、取り出す
中央のテキストボックスに、正規表現パタンを入れて、右隣のボタンを押すと下のテキストボックスに、一致した結果が表示されるようにします。正規表現関連のクラスを使うためには、System.Text.RegularExpressions 名前空間を使います。正規表現パターンと対象文字列を引数で受け取り、一致パターンをクラスメンバ RegexResultに格納します。
まず、正規表現を使って一致を取得するクラスを作成します。
using System.Text.RegularExpressions;
class DoRegex
{
// 正規表現パターンを格納
public string regexPattern;
// 取得した一致パターンを格納
public string RegexResult;
public DoRegex(string pattern, string targetStr)
{
Regex r = new Regex(pattern);
Match m = r.Match(targetStr);
while (m.Success)
{
RegexResult = RegexResult + m.Value + "\n";
m = m.NextMatch();
}
}
}その結果、GetWeb.csファイルは、以下のようになります。
using System.IO;
using System.Net;
using System.Text.RegularExpressions;
namespace WebRegex01
{
class GetHtmlTexte
{
// 取得したhtmlテキスト
public string result;
// コンストラクタ urlを与えると、resultにhtmlテキストを入力する
public GetHtmlTexte(string url)
{
WebClient wc = new WebClient();
try
{
using (Stream stream = wc.OpenRead(url))
using (StreamReader sr = new StreamReader(stream))
{
// Add a user agent header in case the
// requested URI contains a query.
// 要求されたURIに、問合せが含まれる場合に備えて、
// ユーザー・エージェント・ヘッダを追加します。
wc.Headers.Add("user-agent", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.0.3705;)");
string str = sr.ReadToEnd();
result = str;
}
}
catch
{
// Let the user know what went wrong.
// ユーザーに、何が問題になったのかを知らせます。
// The file could not be read:
result = "指定されたサイトを読み取れませんでした:";
}
}
}
class DoRegex
{
// 正規表現パターンを格納
public string regexPattern;
// 取得した一致パターンを格納
public string RegexResult;
public DoRegex(string pattern, string targetStr)
{
Regex r = new Regex(pattern);
Match m = r.Match(targetStr);
while (m.Success)
{
RegexResult = RegexResult + m.Value + "\n";
m = m.NextMatch();
}
}
}
}MainWindow.xamlを以下コードを参考に変更します。具体期には、中央右のボタンにクリックイベントを追加しました。
<Window x:Class="WebRegex01.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:local="clr-namespace:WebRegex01"
Title="MainWindow" Height="400" Width="600">
<Grid>
<Grid.RowDefinitions>
<RowDefinition Height="*"/>
<RowDefinition Height="Auto"/>
<RowDefinition Height="*"/>
</Grid.RowDefinitions>
<DockPanel Name="targetURL" Grid.Row="0">
<DockPanel DockPanel.Dock="Top">
<Button Name="urlAcsses"
DockPanel.Dock="Right"
Width="100"
Click="urlAcsses_Click">Button</Button>
<TextBox Name="urlAdress">TextBox</TextBox>
</DockPanel>
<TextBox Name="htmlText"
AcceptsReturn="True"
VerticalScrollBarVisibility="Auto">TextBox</TextBox>
</DockPanel>
<GridSplitter Grid.Row="1" Height="2" HorizontalAlignment="Stretch" />
<DockPanel Grid.Row="2">
<DockPanel DockPanel.Dock="Top">
<Button Name="doRegex"
DockPanel.Dock="Right"
Width="100"
Click="doRegex_Click">Button</Button>
<TextBox Name="regexFormula">TextBox</TextBox>
</DockPanel>
<TextBox Name="regexResult" AcceptsReturn="True">TextBox</TextBox>
</DockPanel>
</Grid>
</Window>Window.xaml.csファイルを以下のように変更します。
using System.Windows;
namespace WebRegex01
{
/// <summary>
/// MainWindow.xaml の相互作用ロジック
/// </summary>
public partial class MainWindow : Window
{
public MainWindow()
{
InitializeComponent();
urlAdress.Text = "https://webdesign.vdlz.xyz/index.html";
regexFormula.Text = "<a href=\"(.*?)\".*?>";
}
private void urlAcsses_Click(object sender, RoutedEventArgs e)
{
string url = urlAdress.Text;
GetHtmlTexte gethtml = new GetHtmlTexte(url);
htmlText.Text = gethtml.result;
}
private void doRegex_Click(object sender, RoutedEventArgs e)
{
string rPattern = regexFormula.Text;
DoRegex RResult = new DoRegex(rPattern, htmlText.Text);
regexResult.Text = RResult.RegexResult;
}
}
}インターネット上のhtmlファイルから情報を取得するプログラムを作成する的な方法を確認できました。いろいろな活用方法がありそうです。
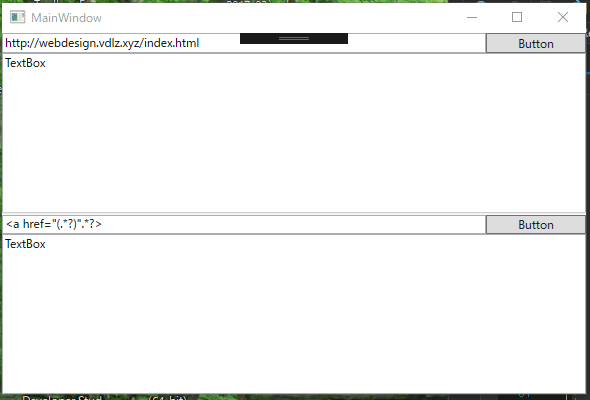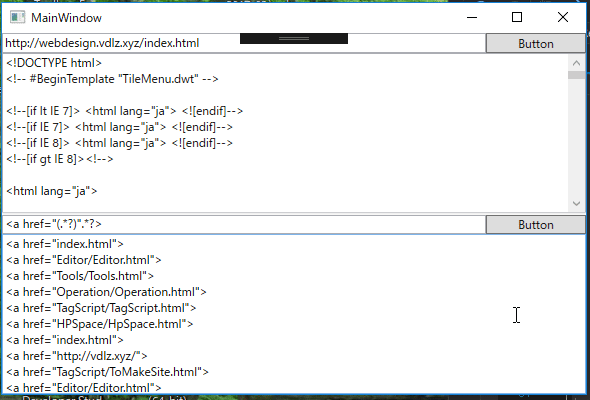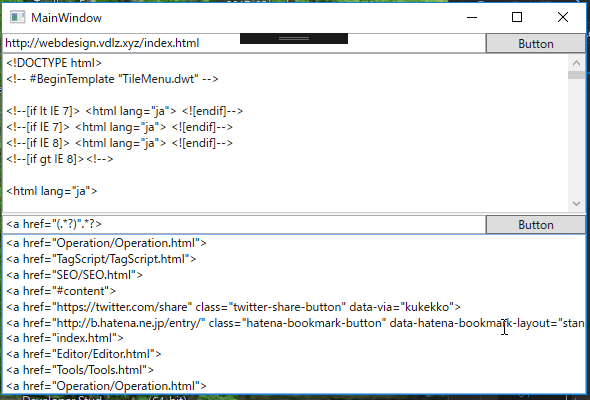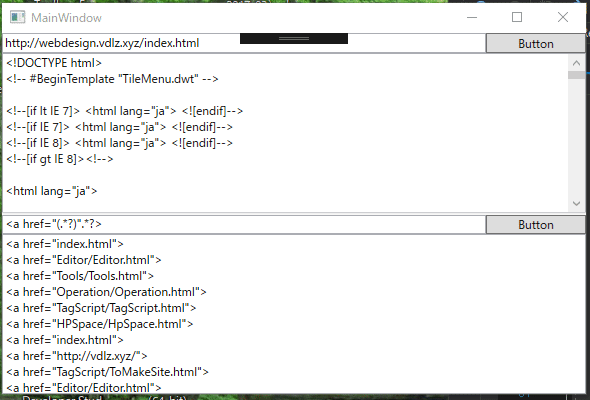
続き
正規表現で、部分文字列を取得することで、aタグのURL部分だけを取得します。
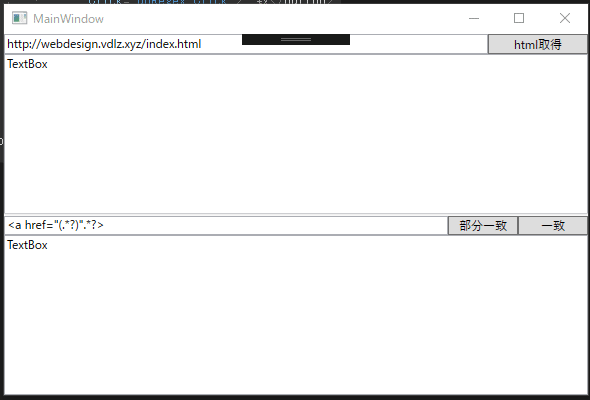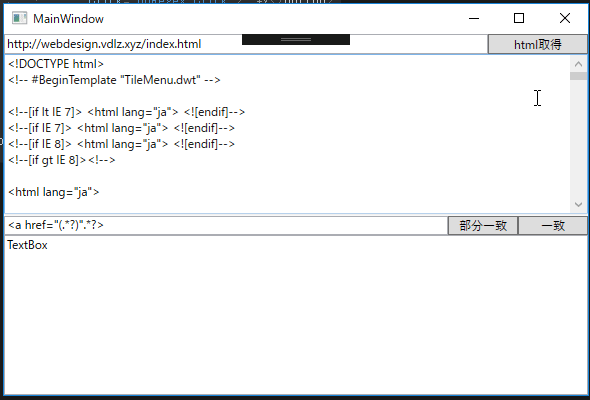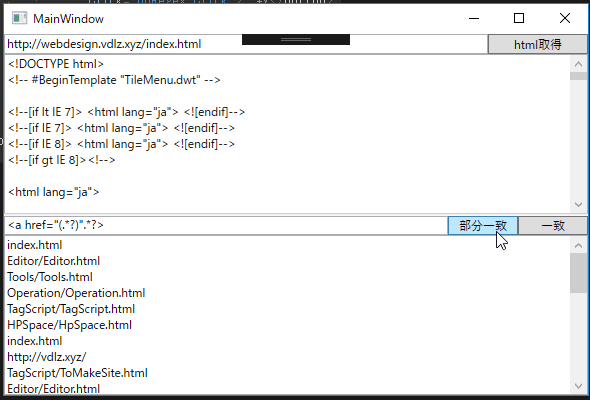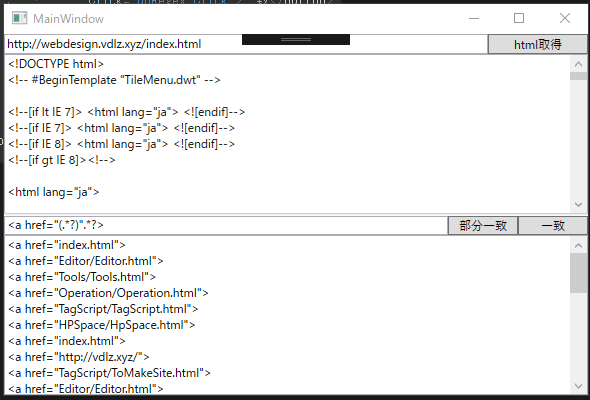
正規表現を使って、その前後の文字列のパターンによって囲まれた文字列を取得することは、部分文字列を取得することで実現できます。Webサイトのhtmlテキストを取得し、正規表現を使って文字列を取り出すサンプルです。