C#で利用できるhtmlパーサーのAngleSharpには、codeproject内にも、いくつかのサンプル・コードとドキュメントが、存在します。
原文「AngleSharp」
概要
Introduction
今日では、すべてが、Webの周辺に集中しています。私たちは、常に、データをダウンロードしたりアップロードしたりしています。ユーザーが、それらのデータを同期させることを望むため、また、私たちのアプリケーションは、更に、おしゃべりになっています。一方では、更新プロセスは、私たちのアプリケーションのふれが大きい部分をクラウドに、配置することによって、ますます直接的になっています。
Web全体の動きは、バイナリ・データと一緒にやってくるだけではありません。出力のほとんどが、最終的に、HTMLとして知られている、いくつかの記述コードにレンダリングされるため、動作は、主にHTMLによって忙しくしています。この記述言語は、2つの素敵な追加で装飾されます。:CSS3(まだ、別の記述言語)のフォ-ムのスタイルとJavaScript(公式にECMAScriptとして指定された)のフォ-ムのスクリプト。
この止められない傾向は、現在、10年に比べて、さらに勢いを獲得しています。現在、うまく設計されたWebページを持っていることは、すべての会社のかなめです。優れたところは、HTMLが、かなり単純であるということで、さらに、プログラミング知識のない人でも、ページを作成することができます。最も単純な近似では、私たちは、ファイル内のいくつかのテキストを挿入するだけです。そして、(おそらくファイルを* .htmlに変更した後)ブラウザ内の、それを開きます。
手短に言うと:私たちのアプリケーションでさえ、私たちは、ときどき、HTMLを配信するために、Webサーバーと通信する必要がある場合があります。これは極めてうまく洗練されて、フレームワークによって解決されます。私たちは、必要なTCPとHTTPアクションを知ることによって、全体の通信を処理する、強力なクラスを持っています。しかしながら、一旦、私たちは、基本的に失う文書上で、いくつかの操作を行う必要があります。これが、AngleSharpが活躍する場所です。
Background
AngleSharpのアイデアは、約1年前に生まれました。(そして、私は、AngleSharpが、なぜ、HtmlAgilityPackや類似している解決法を越えるかについて、次の段落で、説明します)。AngleSharpを使用する主な理由は、実際には、あなたが、ブラウザに持っているように、DOMにアクセスすることです。唯一の違いは、この場合、あなたが、C#(あるいは、他のどんな.NET言語)を使用することです。camel caseからpascal caseに、プロパティとメソッドの名前を変更する(設計上)別の違いがあります。(すなわち、最初の文字が、大文字になっています)。
その結果、私たちが、実装について詳しく説明する前に、私たちは、AngleSharpの長期目標に目を通す必要があります。実は、いくつかの目標があります:
- HTML、XML、SVG、MathMLとCSSのためのパーサ
- CSSスタイルシート/スタイル規則を作成する。
- 文書のDOMを返す
- DOMで修正を実行する
- *利用可能なレンダラの基礎を提供する
コア・パーサは、確実に、HTML5パーサによって与えられます。HTML文書に、スタイルシート参照とスタイル属性が含まれているため、CSS4パーサーは、自然な追加機能です。(また、HTML文書でも発生する可能性がある)SVGとMathMLは、XML文書として解析することができるため、優れた追加の現在のW3C仕様に対応している、他のXMLパーサを持っています。唯一の違いは、生成された文書にあります。それは、異なるセマンティクスを持ち、異なるDOMを使用しています。
* pointは、かなり面白いです。この背後にある基本的な考え方は、C#で書かれているブラウザが、AngleSharp上に構築されるということではありません。(しかしながら、それは、発生できます)。動機づけは、ここで、スタイルのためのCSSによる記述言語として、HTMLを使用しているクロスプラットフォームのUIフレームワークの、新しいものを作成することにあります。もちろん、これは、非常に野心的な目標です。そして、それは、確実に、このライブラリでは、解決されません。しかしながら、このライブラリは、このフレームワークの作成において、重要な役割を果たすでしょう。
次の2つのセクションでは、私たちは、HTML5とCSS4パーサを作成する際の重要な手順について説明します。
HTML5パーサ
HTML5 parser
HTML5パーサーは、角括弧だけでなく、さらに多くを処理する必要があるため、ほとんどの人々が考えるより、HTML5パーサを記述することは、遥かに難しいです。主な問題は、うまく定義されていない文書/文書の断片では、多くのエッジケースが発生することです。また、フォーマットは、一部のタグが、他とは異なる扱いをする必要があるため、それほど簡単ではありません。
全体として、公式の仕様のないパーサのような、記述をすることができます。しかしながら、1つは、全てのエッジケース(そして、コードや紙の上に、それらを導入することを管理する)、あるいは、パーサは、単純に、全てのWebページの一部で、動作しているだけのいずれかを知っている必要があります。
ここでは、仕様は多くの助けになり、私たちに、可能なすべての変化過程で、可能な状態の全ての範囲を与えます。主な作業の流れは、とても単純です。:私たちは、Streamから開始します。それは、直接、ローカル・マシンのファイルから、ネットワークからのデータ、あるいは、既に取得した文字列のどれかからができます。このStreamは、Streamと既に読まれたコンテンツのバッファの読み込みの流れが制御され、プリプロセッサに与えられます。
最後に、私たちは、プリプロセッサから、一連の役に立つオブジェクトにデータを変換する、いくつかのデータをトークナイザーに渡す準備ができています。これらの一時オブジェクトは、続いて、DOMを構築するために、使用されます。ツリーの構築は、幾度もトークナイザーの状態を切り替える必要がある場合があります。
次のイメージは、HTML文書を解析するために使用される、一般的なスキームを表示します。
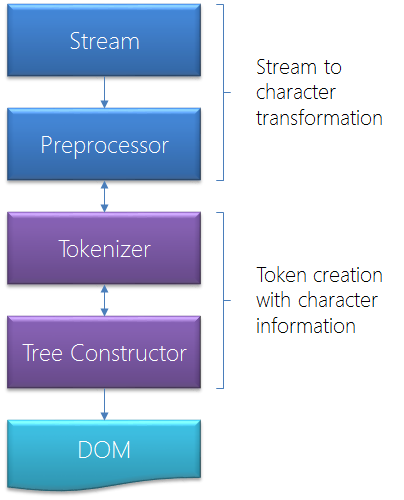
このヘルパーは、より少ないStreamハンドラです。それが、Streamインスタンスを取得するため、そして、検出されたエンコードで、それを読みます。また、それは、読み取り工程中にエンコードを変更することもできます。将来は、このクラスは、これまで、Streamから与えられたEncodingで、テキストを読み込むために、TextReaderクラスに基づいたため、変更されるかもしれません。将来は、カスタム・クラスで、それを処理するほうが良いかもしれません。それは、すぐに使える別のエンコーディングで、後ろ向きの読取りをサポートしています。
ツリー構造
Tree construction
一旦、私たちが、トークンの作業ストリームを取得した場合、私たちは、DOMを構築し始めることができます。私たちが、処理する必要がある、いくつかのリストが、あります。:
- 現在のタグを開く。
- アクティブな書式設定要素。
- 特別なフラグ。
最初のリストは、完全に明らかです。私たちが、他のタグが含まれている、タグを開くため、私たちは、道を一緒に取得した、パスの種類を記憶する必要があります。2つ目のものは、それほど明白でありません。現在開いている要素には、挿入された要素に何らかのフォーマット効果があることが考えられます。このような要素は、書式設定要素とみなされます。優れた例は、<b>タグ(ボールド)です。適用されたすべての*含まれた要素は、太字で表示されます。いくつかの例外(*)が、ありますが、これが、HTML5が、些細でない理由です。
<pre contenteditable>HTMLパーサーは、<pre>タグを<<html>タグや<body>タグの前に、リーガルタグとして認識しません。このように、代替品が、初期化されます。それは、最初に<html>タグを挿入し、その後に<body>タグを挿入します。直接、<body>タグを<html>タグに挿入し、また、(空の)<head>要素が、作成されます。最後に、ファイルの終わりのすべてが、閉じられ、私たちの<pre>ノードが、また、する必要があることとして、閉じられていることを示します。
<html>
<head/>
<body>
<pre contenteditable=""></pre>
</body>
</html>ツリー・コンストラクタの状態を検証するために、とても適している、ハードエッジのケースがあります。以下は、「ハイゼンベルグ型アルゴリズム」が適切に動作しており、表とアンカータグの使い方に従わない場面で、呼び出されている場合、調べるための優れたテストです。この呼び出しは、別のアンカー要素を挿入するときに行う必要があります。
<a href="a">a<table><a href="b">b</table>x結果として得られるHTML DOMツリーは、(<html>、<body>などのタグなしで)次のスニペットによって与えられます。:
<a href="a">
a
<a href="b">b</a>
<table/>
</a>
<a href="b">x</a>ここでは、私たちは、文字bが、<table>から取り出されていることがわかります。ハイパーリンクは、その結果、表の前で開始し、その後に継続される必要があります。この結果、アンカー・タグが重複します。全体として、それらの変化は、些細ではありません。
表は、いくつかのエッジ・ケースのための役割を果たします。エッジ・ケースの大部分は、表の中のセルを持たない環境のテキストによるものです。次の例は、これを説明します。:
A<table>B<tr>C</tr>D</table>ここでは、私たちは、<td>や<th>の親を持っていない、いくつかのテキストを持っています。結果を、次に示します。:
ABCD
<table>
<tbody>
<tr/>
</tbody>
</table>全てのテキストは、実際の<table>要素の前に移動します。さらに、私たちが、定義された<tr>要素を持っているため、しかし、<tbody>、<thead>、<tfoot>のいずれも、<tbody>セクションには、挿入されません。
もちろん、目を満たす以上のものがあります。HTML5構文を検証する大きな部分は、エラー訂正と表の作成にあります。また、書式設定要素は、いくつかの規則を満たす必要があります。詳細に興味を持つ人は誰でも、コードを調べる必要があります。コードが、通常のLOBアプリケーション・コードと同じくらい読みにくい場合でも、適切なコメントと挿入された領域で、読むことが可能なはずです。
テスト
Tests
非常に重要な点は、単体テストを統合することでした。複雑なパーサ設計のために、作業の大半は、TDDの思考体系を要求されませんでした。しかしながら、コードの行が記述される前に、テストが行われている部分もあります。全体として、広範囲にわたる単体テストを配置することは重要でした。HTMLパーサのツリー・コンストラクタは、テスト・ライブラリの主な目標の1つです。
また、DOMオブジェクトは、単体テストの対象となっています。ここでの主な目的は、これらのオブジェクトが、期待どおりに動作していることを確実にするためでした。これは、定義された無効な操作にエラーを投げるだけであることを示しています。そして、統合した結合機能は、機能的です。このようなエラーは、ツリー・コンストラクタは、無効な操作を決してしないことを期待するため、解析処理中には発生しません。
他のテスト環境は、データベースから、Webページをクロールすることを目指している、AzureWebStateプロジェクトで設定されています。これは、それを、簡単に、パーサで、(StackOverflowExceptionやOutOfMemoryExceptionのような)深刻な、あるいは、潜在的な性能に関する問題を見つけます。
信頼性試験は、私たちが興味を持っている唯一のテストではありません。私たちが、結果を解析するために、あまりに長く待つ必要がある場合、私たちは、困っているかもしれません。最新のWebブラウザでは、Webページのために1msから100msが必要です。したがって、100msを超えるものは、すべて、最適化する必要があります。幸運にも、私たちは、いくつかの素晴らしいツールを持っています。Visual Studio 2012は、性能を分析するために、素晴らしいツールを提供しています。しかしながら、私のためのいくつかのシナリオでは、PerfViewが、最も良い選択であるようです。(マシン全体で動作し、VSから独立しています)。
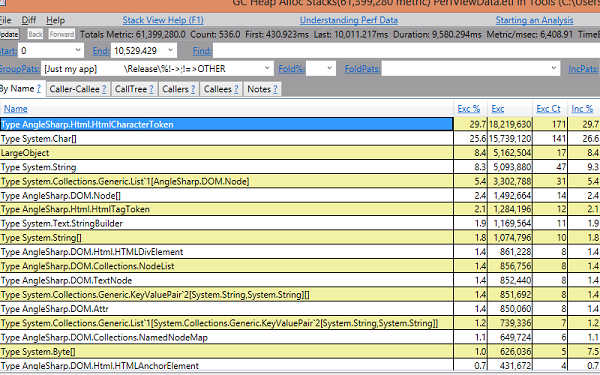
メモリ消費量を簡単に見てみると、いくつかの指標があります。私たちが、全てのHtmlCharacterTokenインスタンスを確保することについて何かしたいと思うかもしれません。ここでは、文字トークンのためのプールは、既に、とても有益でした。しかしながら、最初のテストでは、(処理速度に関する)性能への影響は、ごくわずかであることが示されています。
CSS4パーサ
CSS4 parser
すでに、いくつかのCSSパーサーがあります。それらのうちのいくつかは、C#で書かれています。しかしながら、それらのほとんどは、セレクタを評価しない、あるいは、特定のプロパティや値の特定の意味を無視し、本当に簡単な解析を行います。また、それらのほとんどは、CSS3以前の方法です。あるいは、まったく、(名前空間、インポートなど...)@ -ruleをサポートしていません。
HTMLが、レイアウト/スタイリング言語としてCSSを使用しているため、CSSを直接統合するのは非常に自然なことでした。これがとても役に立つことが、証明された場所が、いくつかあります。:
- Selectorは、QuerySelectorのようなメソッドのために必要です。
- すべての要素は、文字列ではない、DOM表示を持つ、スタイル属性を持つことができます。
- スタイルシートは、DOMで、直接、考慮されます。
- <style>要素は、HTMLパーサにとって、特別な意味を持っています。
現時点では、外部のスタイルシートは、直接解析されません。理由は、とても単純です。:AngleSharpは、外部参照の量を最小限に抑える必要があります。最も理想的な場合には、AngleSharpは、ポータブル・クラス・ライブラリとして、簡単に、移植(または、存在)することができます(共通部分が、「Metro」、「Windows Phone」と「WPF」の間にあります)。特定の時点で、TaskCompletitionSourceを使用するため、これは、現時点では不可能かもしれません。しかし、これは実際には、ライブラリ全体が、Taskインスタンスで装飾されていない、あるいは、さらに、awaitとasyncキーワードで装飾されていない理由です。
トークン化
Tokenization
CSSトークナイザは、HTMLのもののように複雑ではありません。CSSトークナイザをいくらか複雑にするのは、より多くの種類のトークンを処理する必要があるということです。CSSトークナイザには、以下のものがあります。:
- String(一重、あるいは、二重引用符で囲む)
- URL(url()関数の文字列)
- Hash(主に#abcなどのセレクタ用、通常は色用ではありません)
- AtKeyword(@-rulesのための使用される)
- Ident(セレクタ、指定子、プロパティや値で使用される任意の識別子)
- Function(関数は、大部分は値を、ときどき規則を見つけます)
- Number(5や5.2や7e-3のような何らかの数字)
- Percentage(特別な種類の次元の値、例えば10%)
- Dimension(いずれかの次元数、たとえば5px、8emまたは290deg)
- Range(範囲値は、ユニコード値の範囲を作成します)
- Cdo(特別な種類の開かれたコメント、すなわち、<--)
- Cdc(特別な種類の終わりのコメント、すなわち、-->)
- Column(個人的には、私は、これをCSSで見たことがない:||)
- Delim(カンマや単一のハッシュのような区切り文字)
- IncludeMatch(属性セレクタに~=一致を含めます)
- DashMatch(属性セレクタの破線Match |=)
- PrefixMatch(属性セレクタの接頭辞Match ^=)
- SuffixMatch(属性セレクタの接尾辞Match $=)
- SubstringMatch(属性セレクタの部分文字列Match *=)
- NotMatch(属性セレクタの一致しない!=)
- RoundBracketOpenとRoundBracketClose
- CurlyBracketOpenとCurlyBracketClose
- SquareBracketOpenとSquareBracketClose
- Colon(コロンは、プロパティ内の値と名前を区別する)
- Comma(さまざまな値やセレクタを切り離すために使用される)
- Semicolon(主に宣言を終了するために使用する)
- Whitespace(ほとんどの空白文字は、分離の理由だけを持っています-セレクタで意味があります)
CSSトークナイザは、トークンの反復子を返す、単純なストリームに基づいたトークナイザーです。この反復子は、続いて、使用されることができます。CssParserclassのすべてのメソッドは、このような反復子を取得します。反復子を使用する素晴らしい利点は、私たちが、どんなトークン・ソースでも、基本的に使うことができるということです。例えば、私たちは、最初の1つに基づいて、2つ目の反復子を作成するために、他のメソッドを使用できます。このメソッドは、サブセットに対してのみ反復処理を行います。(いくつかの中括弧の内容のように)。素晴らしい利点は、両方のストリームが進むということです。しかし、私たちは、とても複雑なトークン管理を続行する必要はありません。
このため、規則の追加は、次のコード・スニペットと同じくらい簡単です。:
void AppendRules(IEnumerator<CssToken> source, List>CSSRule> rules)
{
while (source.MoveNext())
{
switch (source.Current.Type)
{
case CssTokenType.Cdc:
case CssTokenType.Cdo:
case CssTokenType.Whitespace:
break;
case CssTokenType.AtKeyword:
rules.Add(CreateAtRule(source));
break;
default:
rules.Add(CreateStyleRule(source));
break;
}
}
}ここでは、私たちは、いくつかのトークンを無視します。at-keywordの特別な場合、私たちは、新しい@ -ruleを開始します。それ以外の場合には、私たちは、スタイル規則が、作成されないと仮定します。スタイル規則は、私たちが知っているように、セレクタから開始します。有効なセレクタは、可能な入力トークンに対してより多くの制約を作成します。しかし、一般に、入力として、任意のトークンを取得します。
非常に頻繁に、現在の位置から次の位置まで、空白をスキップする必要があります。次のスニペットでは、これを行うことができます:
static Boolean SkipToNextNonWhitespace(IEnumerator<CssToken> source)
{
while (source.MoveNext())
if (source.Current.Type != CssTokenType.Whitespace)
return true;
return false;
}さらに、また、私たちが、トークン・ストリームの最後に到達する場合、私たちは、情報を取得します。
スタイルシートの作成
Stylesheet creation
スタイルシートは、続いて、すべての情報で作成されます。現在、CSSNamespaceRuleやCSSImportRuleのような、特別な規則は、正しく解析されるが、その後、無視されます。これは将来、ある時点で、統合する必要があります。
さらに、私たちは、CSSPropertyと呼ばれる、とても一般的な(そして、意味がない)プロパティを取得するだけです。将来は、ジェネリック・プロパティは、未知の(あるいは、もう使われていない)宣言だけが使用されています。色のような意味のある宣言には、より特殊なプロパティが使用されています。:#f00やfont-size: 10pt。また、これは、続いて、考慮すべき問題に、必要な入力型を取得する必要がある値の解析に影響します。
もう一つのポイントは、(url()の他の)CSS関数が、まだ含まれていないということです。しかしながら、なぜなら、toggle()とcalc()やattr()関数は、ますます多く使用されているため、これらは、とても重要です。さらに、rgb()+rgba()とhsl()+hsla()などは、必須です。
一旦、私たちが、基本的に、必要な特別な規則のための特別な場合を解析を達成しました。次のコード・スニペットは、これを記述します。:
CSSRule CreateAtRule(IEnumerator<CssToken> source)
{
var name = ((CssKeywordToken)source.Current).Data;
SkipToNextNonWhitespace(source);
switch (name)
{
case CSSMediaRule.RuleName: return CreateMediaRule(source);
case CSSPageRule.RuleName: return CreatePageRule(source);
case CSSImportRule.RuleName: return CreateImportRule(source);
case CSSFontFaceRule.RuleName: return CreateFontFaceRule(source);
case CSSCharsetRule.RuleName: return CreateCharsetRule(source);
case CSSNamespaceRule.RuleName: return CreateNamespaceRule(source);
case CSSSupportsRule.RuleName: return CreateSupportsRule(source);
case CSSKeyframesRule.RuleName: return CreateKeyframesRule(source);
default: return CreateUnknownRule(name, source);
}
}CSSFontFaceRuleの解析が、どのように実装されるかについて見ましょう。ここでは、私たちは、プロセスの所要時間のためのfont-face規則を、オープン規則のスタックにプッシュすることを確認します。これは、すべての規則が、正しく、割り当てられた親の規則を取得することを保証します。
CSSFontFaceRule CreateFontFaceRule(IEnumerator<csstoken> source)
{
var fontface = new CSSFontFaceRule();
fontface.ParentStyleSheet = sheet;
fontface.ParentRule = CurrentRule;
open.Push(fontface);
if(source.Current.Type == CssTokenType.CurlyBracketOpen)
{
if (SkipToNextNonWhitespace(source))
{
var tokens = LimitToCurrentBlock(source);
AppendDeclarations(tokens.GetEnumerator(), fontface.CssRules.List);
source.MoveNext();
}
}
open.Pop();
return fontface;
}
</csstoken>さらに、私たちは、現在の中括弧内に収まるように、LimitToCurrentBlockメソッドを使用します。もう一つの事は、私たちが、与えられたfont-face規則に宣言を添付するために、AppendDeclarationsメソッドを再利用することです。これは、一般的な規則でありません。例えば、メディア規則は、宣言の代わりに他の規則が含まれます。
テスト
Tests
とても重要なテスト・クラスは、CSSセレクタによって表示されます。これらのセレクタは、(文書を問い合わせることのための、CSSで...)多くの機会に使用されるため、一連の役に立つ単体テストが含まれることが、とても重要でした。幸運にも、(主に、jQueryで使用される)Sizzle Selectorエンジンを保守する人々は、既に、この問題を解決しています。
これらのテストは、次の3つのサンプルのようになります。:
[TestMethod]
public void IdSelectorWithElement()
{
var result = RunQuery("div#myDiv");
Assert.AreEqual(1, result.Length);
Assert.AreEqual("div", result[0].NodeName);
}
[TestMethod]
public void PseudoSelectorOnlyChild()
{
Assert.AreEqual(3, RunQuery("*:only-child").Length);
Assert.AreEqual(1, RunQuery("p:only-child").Length);
}
[TestMethod]
public void NthChildNoPrefixWithDigit()
{
var result = RunQuery(":nth-child(2)");
Assert.AreEqual(4, result.Length);
Assert.AreEqual("body", result[0].NodeName);
Assert.AreEqual("p", result[1].NodeName);
Assert.AreEqual("span", result[2].NodeName);
Assert.AreEqual("p", result[3].NodeName);
}それで、私たちは、既知の結果を評価の結果と比較します。さらに、私たちは、結果の順序にも気をつけています。これは、ツリー・ウォーカーが、正しい事をしていることを示しています。
DOM実装
DOM implementation
与えられたHTMLソースコードのオブジェクト表現を返すことなく、全てのプロジェクトは、全く役に立ちません。言うまでもなく、私たちは、2つのオプションを持っています。:
- 私たちの独自の書式/オブジェクトを定義します。
- 公式の仕様を使用する
プロジェクトの目標のために、決定はとても明らかでした:作成されたオブジェクトは、公開されたAPIを持っている必要があります。これは、公式仕様と同一/非常によく似ています。したがって、AngleSharpのユーザーには、いくつかの利点があります。:
- 学習曲線は、DOMを使い慣れている人には存在しません。
- C#から、JavaScriptへのコードの移植が、さらに簡単になります。
- HTML DOMに精通していないユーザーは、HTML DOMについても学びます。
- すべてが、インテリセンスでアクセスできるため、他のユーザーは、おそらく、同様に、何かを学びます。
最後の点は、ここでは、とても重要です。プロジェクトの巨大な努力は、APIや関数全体の適切なドキュメントを表す(ちょっとことを行い始め)何かを記述しに行きます。その結果、列挙、プロパティ、メソッド、クラスとイベントが文書化されています。これは、いろいろな学習可能性が、利用可能であることを示しています。
さらに、すべてのDOMオブジェクトは、DOMAttribute、あるいは、単にDOMと呼ばれる、特別な種類の属性で装飾されます。この属性は、調べるために、オブジェクト(さらに、StringかInt32のような最も一般的な型)は、JavaScriptのようなスクリプト言語で使用する役に立ちます。ある意味では、これは、最新のブラウザで使用される、IDLを統合します。
また、属性は、プロパティとメソッドを装飾します。特別な種類のプロパティは、インデクサです。ほとんどのインデクサーは、W3Cによる名前の付いた項目です。しかしながら、JavaScriptが、インデクサーをサポートしている言語であるため、私たちは、あまり頻繁に見ることはありません。それにもかかわらず、ここでは、私たちが、それをどのように使うか選択できる装飾が、配置されています。
基本的なDOM構造は、次の図で示されます。
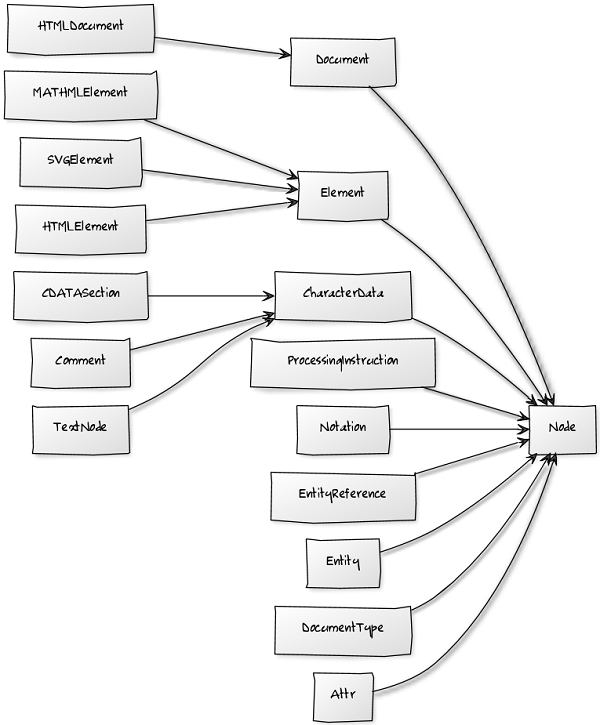
本当に完全な参照を見つけることは、非常に困難でした。W3Cが、公式の標準を作成していますが、それは、多くの場合、それ自体で矛盾があります。問題は、現在の仕様が、DOM4であることです。私たちが、ブラウザを調べる場合、私たちは、利用可能なすべての要素があるわけではなく、追加で他の要素が利用可能であることがわかります。参照点として、DOM3を使用するため、理にかなっています。
AngleSharpは、正常なバランスを見つけようとします。ライブラリには、新しいAPI(今は、すべてが実装されているわけではありません。例えば、全体のイベント・システムや変化過程オブジェクト)のほとんどが含まれています。しかし、また、主要なすべてのブラウザで実装され使用されている、DOM3(や前のバージョン)から、すべてが含まれています。
性能
Performance
全部のプロジェクトは、性能を念頭に置いて設計する必要があります。しかしながら、これは、ときどき、とても美しいコードを見つけることができないことを示しています。また、すべては、主要な目標である、仕様にできる限り近づけてプログラムされました。最初の目的は、仕様を適用し、動作している何かを作成します。これが達成されたあと、いくつかの性能の最適化は適用されました。結局は、私たちは、大きなブラウザで知られているものと比較して、パーサ全体が、実際に、とても速いことを見ることができます。
大きなパフォーマンスの問題は、実際の起動時間です。ここでは、JITプロセスは、MSILコードをマシン・コードにコンパイルするだけでなく、(必要な)最適化を実行することもあります。私たちが、いくつかのサンプルの実行を開始する場合、私たちは、ホット・パスが、まったく、最適化されていないことを、すぐに見ることができます。次のスクリーン・ショットは、典型的な実行を示しています。
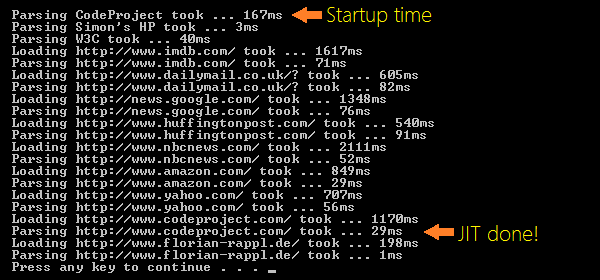
しかしながら、また、JITは、これらの最適化で素晴らしい仕事をしています。コードは、このようなスタイルで記述されています。インライン化やその他の重要な(そして、大部分は取るに足りない)最適化が、JITによって実行される可能性が高いということです。JavaScriptの世界では、非常に重要な速度テストが採用されています。:Slickspeed。このテストでは、さまざまなデータが表示されます。:
- 私たちのCSSトークナイザの性能。
- 私たちのSelectorクリエーターの性能。
- 私たちのツリー・ウォーカーの性能。
- 私たちのCSSセレクタの信頼性。
- 私たちのノード・ツリーの信頼性。
同じマシン上で、JavaScriptの中で最も速い実装では、document.QuerySelectorAllを多用しています。このため、私たちのテストは、ブラウザ(この場合はOpera)とほぼ直接比較しています。最も速い実装は、JavaScriptで約12msかかります。C#では、私たちは、3ms(同じマシン、64ビットCPUによるリリース・モード)で同じ結果を得ることができます。
使用上の注意、この結果は、C#/私たちの実装が、Opera /任意のブラウザより速いことを、あなたに信じさせてはいけません。しかし、それは、性能は、少なくとも揺るぎない領域にあります。ブラウザが、通常、遙かに合理化されており、おそらく高速である点に注意すべきです。しかしながら、AngleSharpの性能は、かなり受け入れることができます。
次のスクリーンショットは、Slickspeedテストの実行中に撮影されました。最初のJavaScript Slickspeedベンチマークで、簡単な比較を確実にする数として、時間が追加されたので、実際の時間の集計は、3msよりも大きいことに注意してください。
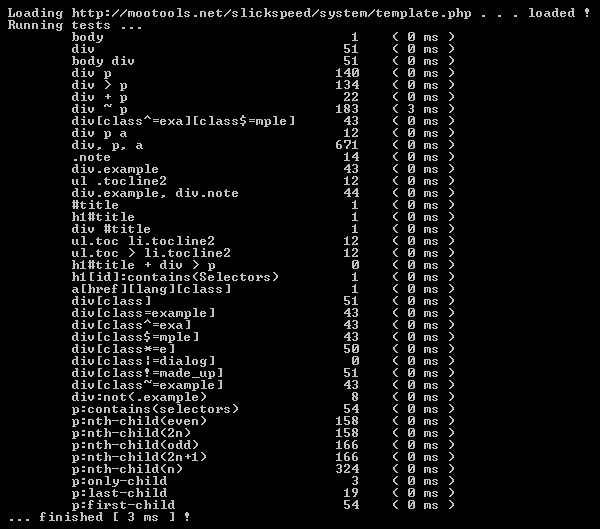
全体で、私たちは、性能が、すでにかなり良いと言えます。さらにしかし、性能の最適化に大きな努力は払われていません。控えめな大きさの文書では、私たちは、確実に100msをはるかに下回り、最終的に(十分なウォームアップ、文書サイズ、CPU速度)、1msに近づくでしょう。
コードを使用する
Using the code
AngleSharpを入手する最も簡単な方法は、NuGetを使用することです。NuGetパッケージへのリンクは、記事の末尾にある(または、NuGetパッケージ・マネージャの公式フィードでAngleSharpを検索するだけです)。
また、GitHubリポジトリで利用可能なソリューションには、SamplesというWPFアプリケーションが、含まれています。このアプリケーションは、次の画像のように見えます。:

すべてのサンプルでは、別の方法で、HTMLDocumentインスタンスが使用されます。文書を取得する基本的な方法は、とても簡単です。:
async Task LoadAsync(String url, CancellationToken cancel)
{
var http = new HttpClient();
//Get a correct URL from the given one (e.g. transform codeproject.com to http://codeproject.com)
// 指定されたURLから正しいURLを取得します(例:codeproject.comをhttp://codeproject.comに変換)
var uri = Sanitize(url);
//Make the request
// 要求を作成します
var request = await http.GetAsync(uri);
cancel.ThrowIfCancellationRequested();
//Get the response stream
// 応答ストリームを取得します
var response = await request.Content.ReadAsStreamAsync();
cancel.ThrowIfCancellationRequested();
//Get the document by using the DocumentBuilder class
// DocumentBuilderクラスを使用して、文書を取得します。
var document = DocumentBuilder.Html(response);
cancel.ThrowIfCancellationRequested();
/* Use the document */
/* 文書を使用します。 */
}現在、4つのサンプルの使い方が、説明されています。最初は、DOM-ブラウザです。サンプルは、ナビゲートすることができる、WPFのTreeViewを作成します。TreeViewコントロールには、文書のすべての列挙可能な子とDOMプロパティが、含まれています。文書は、与えられたURLから受け取った、HTMLDocumentインスタンスです。
これらのプロパティを読み取るには、次のコードを使用します。ここでは、私たちは、その要素が、DOMツリーの現在のオブジェクトであると仮定しています。(例えば、HTMLHtmlElementのような文書のルート要素や、Attrのような属性など)。
var type = element.GetType();
var typeName = FindName(type);
/* with the following definition:
次の定義で:
FindName(MemberInfo member)
{
var objs = member.GetCustomAttributes(typeof(DOMAttribute), false);
if (objs.Length == 0) return member.Name;
return ((DOMAttribute)objs[0]).OfficialName;
}
*/
var properties = type.GetProperties(BindingFlags.Public | BindingFlags.Instance | BindingFlags.GetProperty)
.Where(m => m.GetCustomAttributes(typeof(DOMAttribute), false).Length > 0)
.OrderBy(m => m.Name);
foreach (var property in properties)
{
switch(property.GetIndexParameters().Length)
{
case 0:
children.Add(new TreeNodeViewModel(property.GetValue(element), FindName(property), this));
break;
case 1:
{
if (element is IEnumerable)
{
var collection = (IEnumerable)element;
var index = 0;
var idx = new object[1];
foreach (var item in collection)
{
idx[0] = index;
children.Add(new TreeNodeViewModel(item, "[" + index.ToString() + "]", this));
index++;
}
}
}
break;
}
}アイテムを含まない要素にカーソルを移動すると、通常、ツールチップとして、(例えば、int値を表すプロパティは、現在の値を表示する)その値が返されます。プロパティの名前の隣には、正確なDOM型が表示されます。次のスクリーン・ショットは、サンプル・アプリケーションのこの部分を示します。
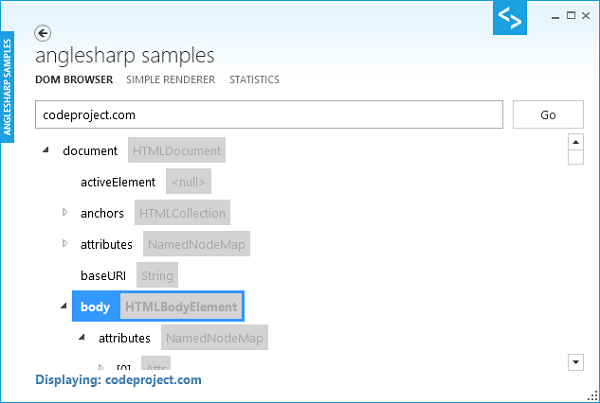
それにもかかわらず、このサンプルは、DOMを使用して、さまざまな種類のオブジェクトに関する情報を取得する方法を示しています。
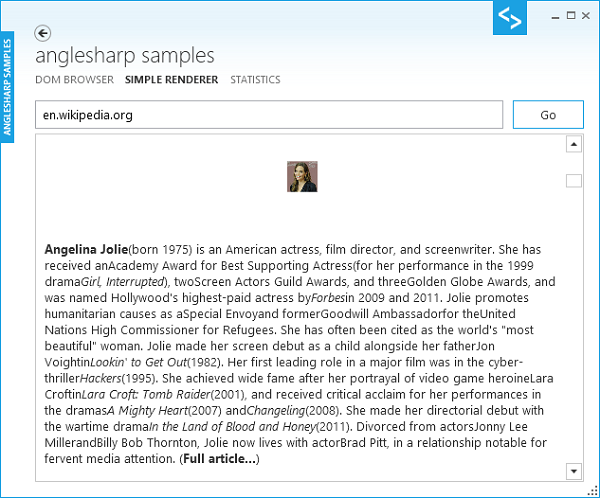
そして、それらの情報を使用します。小さな仕掛けの<img>タグは、同様に、レンダラーであるため、レンダラーに少なくとも少しの色を入れます。このスクリーンショットは、Wikipediaのホームページの英語版にある間に撮影されたものです。
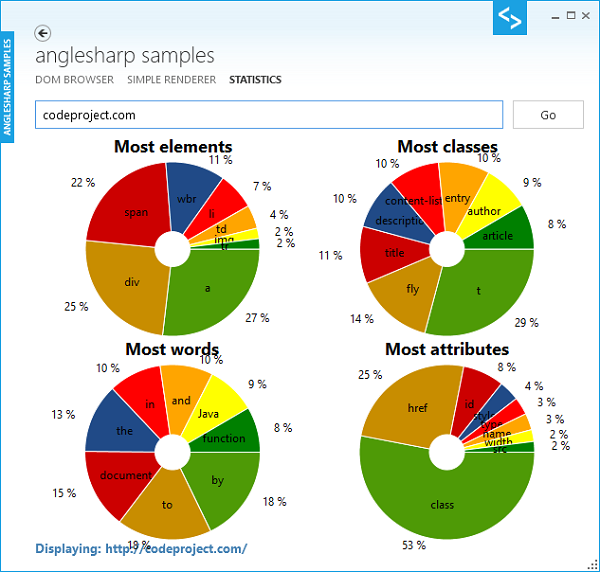
より興味深いのは、統計サンプルです。ここでは、私たちは、指定されたURLからデータを収集します。多かれ少なかれ興味深いかもしれない、利用できる4つの統計があります。:
- top-8要素(最も使用されています)
- top-8クラス名(最も使用されています)
- top-8属性(最も使用されています)
- top-8単語(最も使用されています)
統計デモの中心は、次のスニペットです。:
void Inspect(Element element, Dictionary<String, Int32> elements, Dictionary<String, Int32> classes, Dictionary<String, Int32> attributes)
{
//The current tag name has to be evaluated (for the most elements)
// 現在のタグ名は、(ほとんどの要素のために)評価される必要があります。
if (elements.ContainsKey(element.TagName))
elements[element.TagName]++;
else
elements.Add(element.TagName, 1);
//The class names have to be evaluated (for the most classes)
// クラス名は、(ほとんどのクラスのために)評価される必要があります。
foreach (var cls in element.ClassList)
{
if (classes.ContainsKey(cls))
classes[cls]++;
else
classes.Add(cls, 1);
}
//The attribute names have to be evaluated (for the most attributes)
// 属性名は、(ほとんどの属性のために)評価される必要があります。
foreach (var attr in element.Attributes)
{
if (attributes.ContainsKey(attr.Name))
attributes[attr.Name]++;
else
attributes.Add(attr.Name, 1);
}
//Inspect the other elements
// 他の要素を調べます
foreach (var child in element.Children)
Inspect(child, elements, classes, attributes);
}このスニペットは、文書のルート要素で、最初に使用されます。この時点から、子要素のメソッドを再帰的に呼び出します。後で、LINQを使用して、辞書をソートして評価することができます。
さらに、私たちは、単語の形で、テキスト・コンテンツ上の、いくつかの統計を実行します。ここで、単語は、少なくとも2文字である必要があります。このサンプルでは、OxyPlotは、円グラフを表示するために使用されています。言うまでもなく、CodeProjectは、アンカー・タグ(そうではない人がいる?)、そして、t(私の考えでは、説明を心要としない名前!)と呼ばれるクラスを使用することを好みます。
最後のサンプルは、DOMメソッドquerySelectorAllの使い方を示します。ここでは、C#の命名規則に従って、QuerySelectorAllのように使用します。要素のリストは、TextBox要素のセレクタに入るとフィルタリングされます。ボックスの背景色は、クエリの状態を表します。-赤いボックスは、クエリの構文エラーのために、例外がスローされていることを示しています。
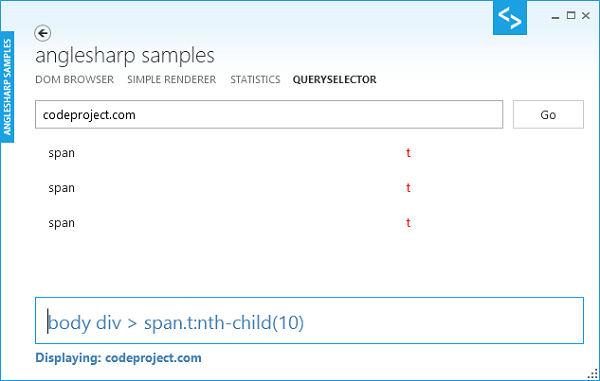
コードは、とても簡単です。基本的に、私たちは、ドキュメントのインスタンスを取得します。そして、セレクタ文字列(*やbody> divなど)を使用して、QuerySelectorAllメソッドを呼び出します。JavaScriptの基本的なDOM構文に精通している人は、すぐにそれを認識します。:
try
{
var elements = document.QuerySelectorAll(query);
source.Clear();
foreach (var element in elements)
source.Add(element);
Result = elements.Length;
}
catch(DOMException)
{
/* Syntax error */
}最後に、私たちは、要素のリストを取得します。(QuerySelectorAllは、私たちに(Elementインスタンスのリストの)HTMLCollectionを提供し、QuerySelectorは、1つの要素、あるいは、nullのみを返します)そして、それをビュー・モデルの観察可能なコレクションにプッシュします。
Update
Update
関心のある別のデモは、スタイルシートの処理であるかもしれません。サンプル・アプリケーションは、任意のWebページを読み込む、短いデモで更新されました。そして、利用可能なスタイルシート(<link>か<style>要素のいずれか)を表示します。
すべての例は、次のようになります。(利用可能なソースは左にあり、スタイルシート・ツリーは右にあります)。
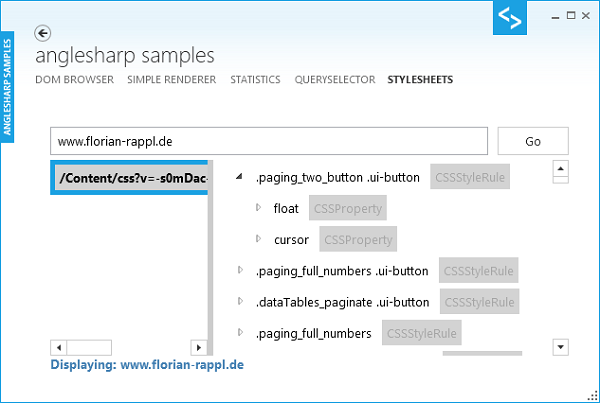
あらためて、必要なコードはあまり複雑ではありません。HTMLDocumentオブジェクトの利用可能なスタイルシートを取得するために、私たちは、そのStyleSheetsプロパティ要素だけを繰り返す必要があります。ここでは、私たちは、CSSStyleSheet型のオブジェクトを取得しませんが、StyleSheetは、取得します。これは、W3Cで指定されたより一般的な型です。
for (int i = 0; i < document.StyleSheets.Length; i++)
{
var s = document.StyleSheets[i];
source.Add(s);
}次の項目で、私たちは、実際に、規則が含まれるCSSStyleSheetを作成する必要があります。ここでは、私たちは、2つの可能性を持っています。:
- スタイルシートは、<style>要素に由来し、インライン化されます。
- スタイルシートは、<link>要素に関連付けられています。そして、外部ソースから読み込む必要があります。
最初のケースでは、私たちは、既に、ソースへのアクセスをしてます。2つ目の場合では、私たちは、まず、CSSスタイルシートのソース・コードをダウンロードする必要があります。大部分の時間が、ソース・コードを受け取るために、使用されるため、私たちは、アプリケーションの応答性を確保する必要があります。
最後に、私たちは、新しい要素(可能なサブノードを持つサブノードを持つノード)を追加します。100のかなりの量で-ちょうどツリーを塗り潰している間少しレスポンシブに状態を保つこと。
var content = String.Empty;
var token = cts.Token;
if (String.IsNullOrEmpty(selected.Href))
content = selected.OwnerNode.TextContent;
else
{
var http = new HttpClient { BaseAddress = local };
var request = await http.GetAsync(selected.Href, cts.Token);
content = await request.Content.ReadAsStringAsync();
token.ThrowIfCancellationRequested();
}
var css = DocumentBuilder.Css(content);
for (int i = 0, j = 0; i < css.CssRules.Length; i++, j++)
{
tree.Add(new CssRuleViewModel(css.CssRules[i]));
if (j == 100)
{
j = 0;
await Task.Delay(1, cts.Token);
}
}決め手となる部分は、実際に、CSSStyleSheetオブジェクトを構築することのためにDocumentBuilder.Cssを使うことです。CssRuleViewModelでは、それぞれが、適切に表示されることを確実にするための、さまざまな規則の間で、区別の問題だけです。3種類の規則があります。:
- 宣言を含むルール(Styleプロパティを使用)。例:Keyframe、Style。
- 他のルールを含むルール(CssRulesプロパティを使用)。例:Keyframes、Media。
- 何も含まれていない規則(特殊なプロパティを使用する)あるいは、特別なコンテンツがあります。例:Import、Namespace。
次に示すコードは、これらの型の基本的な違いを示しています。CSSFontFaceRuleが、第3の分類に属していることに注意して下さい。-それは、特別な宣言の設定のフォ-ムで、特別なコンテンツを持っています。
public CssRuleViewModel(CSSRule rule)
{
Init(rule);
switch (rule.Type)
{
case CssRule.FontFace:
var font = (CSSFontFaceRule)rule;
name = "@font-face";
Populate(font.CssRules);
break;
case CssRule.Keyframe:
var keyframe = (CSSKeyframeRule)rule;
name = keyframe.KeyText;
Populate(keyframe.Style);
break;
case CssRule.Keyframes:
var keyframes = (CSSKeyframesRule)rule;
name = "@keyframes " + keyframes.Name;
Populate(keyframes.CssRules);
break;
case CssRule.Media:
var media = (CSSMediaRule)rule;
name = "@media " + media.ConditionText;
Populate(media.CssRules);
break;
case CssRule.Page:
var page = (CSSPageRule)rule;
name = "@page " + page.SelectorText;
Populate(page.Style);
break;
case CssRule.Style:
var style = (CSSStyleRule)rule;
name = style.SelectorText;
Populate(style.Style);
break;
case CssRule.Supports:
var support = (CSSSupportsRule)rule;
name = "@supports " + support.ConditionText;
Populate(support.CssRules);
break;
default:
name = rule.CssText;
break;
}
}さらに、さらに、それらは、表示されたと同じぐらい選択的である必要はありませんが、宣言と値は、同様に、それら独自のコンストラクタを持っています。
Update 2
AngleSharpを使用する他の興味深い(しかし、明らかな)可能性は、HTMLツリーを読み出すことです。前に述べたように、パーサは、結果として得られるツリーが、(パーサによって適用された様々な例外/許容誤差のため)些細でないことを示している、HTML5の解析規則をアカウントに取得します。
それにもかかわらず、特別な構文解析規則を、少しも必要としない、ほとんどのページは、可能な限り有効にしようとします。次のスクリーンショットは、ツリー・サンプルの外観を示しています。:
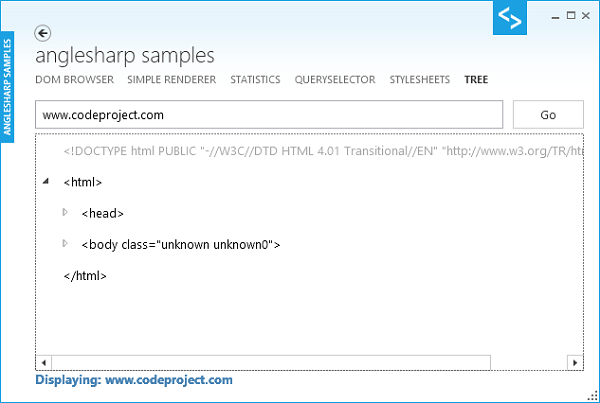
このコードは、それほど複雑ではないように見えるかもしれません。しかしながら、それは、さまざまな種類のノードを区別します。これは、(定義されるように)文書ツリーのテキスト・ノードになった新しい行を隠すために行われます。加えて、複数のスペースは、1つの空白文字に結合されます。
public static TreeNodeViewModel Create(Node node)
{
if (node is TextNode) //Special treatment for text-nodes
// テキスト・ノードのための特別な処理
return Create((TextNode)node);
else if (node is Comment) //Comments have a special color
// コメントは、特別な色を持っています。
return new TreeNodeViewModel { Value = Comment(((Comment)node).Data), Foreground = Brushes.Gray };
else if (node is DocumentType) //Same goes for the doctype
// doctypeについても同じです
return new TreeNodeViewModel { Value = node.ToHtml(), Foreground = Brushes.DarkGray };
else if(node is Element) //Elements are also treated specially
// また、Elementは、特別に扱われます。
return Create((Element)node);
//Unknown - we don't care
// 未知-私たちは、気にかけません
return null;
}Elementは、子供が含まれているかもしれないため、それぞれに扱う必要があります。それゆえに、私たちは、次のコードを必要とします。:
static TreeNodeViewModel Create(Element node)
{
var vm = new TreeNodeViewModel { Value = OpenTag(node) };
foreach (var element in SelectFrom(node.ChildNodes))
{
element.parent = vm.children;
vm.children.Add(element);
}
if (vm.children.Count != 0)
vm.expansionElement = new TreeNodeViewModel { Value = CloseTag(node) };
return vm;
}私たちが、SelectFromメソッドを調べるとき、円が閉じます。:
public static IEnumerable<TreeNodeViewModel> SelectFrom(IEnumerable<Node> nodes)
{
foreach (var node in nodes)
{
TreeNodeViewModel element = Create(node);
if (element != null)
yield return element;
}
}ここでは、私たちは、すべてのノード上に繰り返す反復子だけを返します。そして、もしあれば、作成されたTreeNodeViewModelインスタンスを返します。
関心のポイント
Points of Interest
私が、このプロジェクトを始めたとき、私は、既に、JavaScriptプログラマーの視点から、公式のW3C仕様とDOMを、とても使い慣れていました。しかしながら、仕様の実装は、一般的なWeb開発に関する知識だけでなく、(可能な)パフォーマンスの最適化や興味深い(まだ広く知られていない)問題についても向上させました。
私は、C#で、よく維持管理されているDOM実装を持つことは、間違いなく将来のためになることだと思います。私は、現在、他の事をするのに忙しいですが、これは、一種のプロジェクトです。私は、間違いなく、次の数年間追求します。
これは、私が、少し注目を集めることができることを願っています。そして、何人かの人たちは、プロジェクトに、いくつかのコードをコミットすることに興味があります。C#で、素晴らしい、洗練された(そして、可能な限り完璧な)HTMLパーサの実装を取得することは、本当に素晴らしいでしょう。
参照
References
W3Cが、提供する優れたドキュメントと仕様はなく、全体の仕事は、可能ではなかっただろう。他が、完全に、素晴らしく、最新の間、私は、いくつかの文書が、あまり役に立たない、あるいは、時代遅れのように思えることを認める必要があります。(たいていは、ごくわずかな)間違いが見つかる可能性があるため、また、それらのいくつかの点で質問するために、とても重要です。
- HTML 5.1仕様(草稿)
- CSS構文
- CSSセレクタ
- 文字の定義
- XML 1.1仕様(推奨)
- XHTML構文
- CSS Selector 4(草稿)
- CSS 2.1プロパティ
- WHATWG HTML標準
もちろん、役に立つ、いくつかの他の文書があります。(これらのすべてが、W3CやWHATWGによって提供されています)しかし、上記の一覧は、優れた開始点です。
さらに、次に示すリンクは、役に立つかもしれません。: