「本格読取5」は、ソースネクストが販売するOCRアプリケーションです。
他のOCR製品と比較して安価です。しかし、体験版が存在しないので、実際の使い心地は購入して使用してみないとわかりません。
日本語の文書の認識は、特に機能的に問題ないと感じたので、英文を認識する際の操作と使い心地について紹介します。
「本格読取5」は、英文を読み取るために使用できるか
既に、持っていている場合、英文を認識させる目的で使ってみるのもよいかと思います。しかし、購入して、インストールしてすぐの状態では、ちょっと、残念な感じです。少し学習に手間がかかります。誤認識が少なくなって、快適な状態になるまで、複数の文章を認識させ、認識枠内で修正してく必要があります。
そのため、新たに購入する場合、英文を認識する目的であれば、積極的にはお勧めしません。
ある程度根気よく、学習させた場合、私が持っているeTypist 10での英語認識と比較すると、「本格読取5」の方が良好な気がします。カッコやピリオド、コンマなどの認識では、むしろ「本格読取5」の方が、明らかに良好です。もちろん、最新版(記事を書いている時点では、eTypist 15)と比べたらどうかわかりません。
ソースネクストで、マイページをもっていれば、「毎日ジャンジャン宝くじ」、そして、セールなどで安く購入できる場合があります。
実際に購入したので、使い心地を紹介します。
気が付いた特徴
- 英文認識モードは存在しない。(欧文認識用のOCRエンジンをもっていない。つまり、切り替えて利用できない)
- 領域枠の削除機能ツールボタンは、存在しない。(選択してDelキーで領域を削除できる)
- 領域枠の認識順序の変更は、1つ1つ順番に指定し直すことで変更する。
- 領域枠のアンドゥは、1回のみ。
- 画像が大きいと開けない(閾値は不明、7372×4743, 512dipのjpgファイルは開けない)
- 32 bitアプリケーション
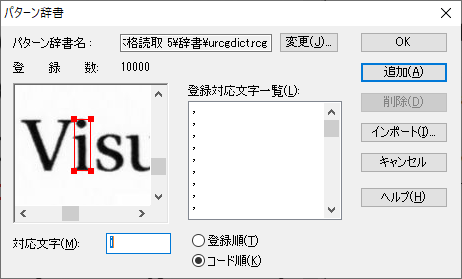
- パターン辞書の登録上限数は、10000です。
動作確認に使用したバージョンは、5.00です。

OCRの予備知識
OCRを使ったことのない人のために、はじめに、独断と偏見に満ちた正確性の怪しい説明を行います。
OCRアプリケーションは、以下の工程で、画像に映った文字から、テキストデータを取り出します。
- 画像の読み込み
- 画像の修正
- 認識領域の指定
- 画像の認識
- テキストの修正(認識辞書の更新)
- テキストの出力
画像から、文字を認識する部分は、「本格読取 5」では、パナソニック社製の高精度OCRエンジンを使用しています。
認識領域の認識部分と、インストール時点での認識辞書がどれだけ育っているかが、製品を使い始めた時点での使い心地に大きく影響しているはずです。
画像の読み取り
画像の読み取りは、[ファイル]メニューから、以下の5つから選択できます。
- デジタルカメラ入力
- TAWAINディバイス入力
- 画像ファイルを開く
- クリップボード画像の入力
- 画面キャプチャー入力
画像ファイルであれば、エクスプローラーから、画像をドラッグ&ドロップしても指定できます。
※本格読取5が、32bitアプリケーションである制約からか、画像が大きいと開けない(閾値は不明、7372×4743, 512dipのjpgファイルは開けない)場合があります。
画像の修正
OCRは、一般に、文字が傾いていると、認識精度が低下します。そのため、認識させる前に、文字が傾いていたら傾きを修正します。
ツールは、[画像]メニューにあります。
![ツールは、[画像]メニューにあります。](Images/ImageMenu.png)
私は、この機能は使用せずに、グラフィック・アプリケーションであらかじめ傾きを修正しています。
認識領域の指定
画像を読み込むと、認識領域を指定する状態になっています。マウスで、矩形で囲んで、画像内の文字を認識したい部分を指定します。領域を指定した順序で認識します。
領域を削除するには、領域を選択し、Delキーを押します。
![[領域]メニュー](Images/AriaMenu.png)
認識順序を変更したい場合は、[領域]メニューの[読取順序変更]を選択し、読み取る順番に、認識領域を指定します。
画像の認識
認識ボタンを押すと認識が開始されます。
認識を実行すると、画層と認識テキストが並べて表示されます。
認識の誤りがあれば、できるだけ認識テキストが表示された領域で修正します。これは、このアプリケーション内で修正した結果が学習され、次回以降の認識結果が改善される可能性が高いからです。
キーボードから直接入力して修正する事もできます。そして、修正ツールを使って修正することもできます。
認識の修正
認識の修正は、出力されたテキストを、汎用テキストエディタのマクロやスクリプト言語を使用して、検索置換リストを用意してまとめて行ってしまいたい衝動にかられると思います。
しかし、本格読取5内の認識テキストを修正する事で、認識辞書が成長するため、根気よく修正していく必要があります。ただ、ソフトウェアの設計思想により、学習による誤変換を避けることができない事例もあると思います。それが許容できない場合は、別のOCRアプリケーションの使用を検討する必要があります。
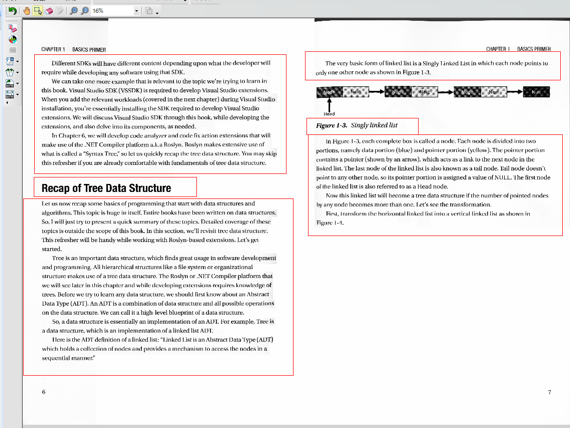
1つの文字が複数の文字として認識される場合
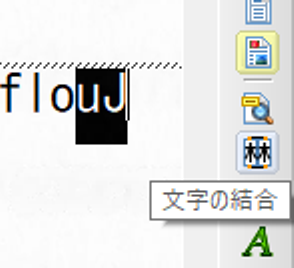
文字を結合します。
複数の文字と認識された文字を選択し、文字の結合をクリックします。
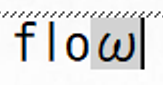
文字が結合され、新たな認識結果が表示されます。
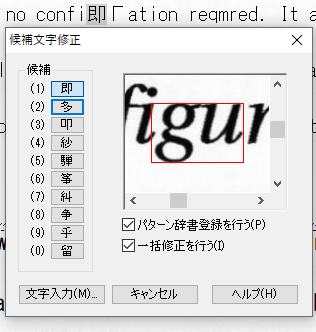
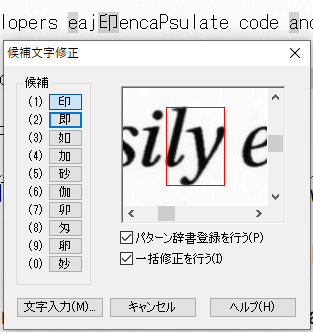
文字が間違って認識されている場合
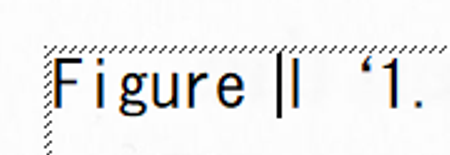
認識を修正します。
間違って認識された文字の前にカーソルを移動し(マウスでクリック)、ダブルクリックします。
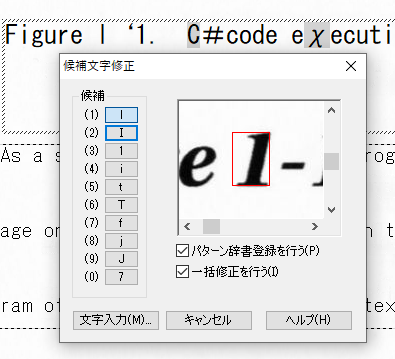
候補文字修正メニューが表示されます。左側に、候補の一覧が表示されますが、文字によっては、表示が小さすぎて判別つかない場合があります。これは、アプリケーションが、高解像度ディスプレイへの対応が不十分で、高解像度ディスプレイの使用を考慮したデザインがされていないことを示しています。左下に、[文字入力]ボタンがあるので、このボタンを押してキーボードから入力したほうが確実です。
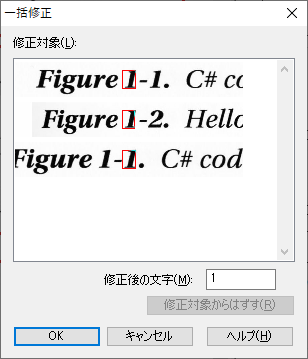
文字を指定すると、類似した文字の一覧が表示されます。一覧から項目を表示すると、認識画像、認識結果テキストの該当部分が選択されて見えるように移動します(認識画像は、移動がきちんと動作しておらず、見えない領域にあることが多々あります)。今回修正する文字と違う文字を選択し、右下の[修正対象からはずす]ボタンを押して、リストから削除します。リストは、Ctrlキーを押して選択すると複数選択ができ、マウスでドラッグしても複数選択ができます。リスト内の項目を同じ認識文字だけにして、[OK]をクリックすると、一度にまとめて修正されます。
残念なことに、ウィンドウを広げることができないので、項目がたくさんあると、必要ない項目を「修正作業から外す」作業が大変です。
複数の文字が1つの文字と認識される場合
![複数の文字が1つの文字と認識された文字を選択し、[文字の分離]を選択します。](Images/gi_bunri.png)
画像をみて、文字の区切りを指定します。
複数の文字が1つの文字と認識された文字を選択し、[文字の分離]を選択します。文字の分離ツールには、2つに分離するツールと、複数の文字に分離するツールがあります。必要に応じて使い分けて下さい。
画像が表示されるので、区切り位置を指定します。
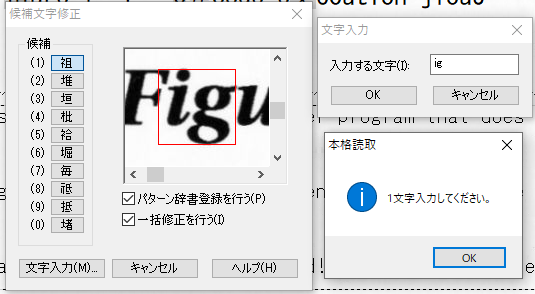
複数の文字が1つの文字として、認識されるのであれば、その画像を複数の文字に割り当てれば、誤認識が減るのではと誰しもが考えると思います。
残念ながら、1つ以上の文字を指定することができません。
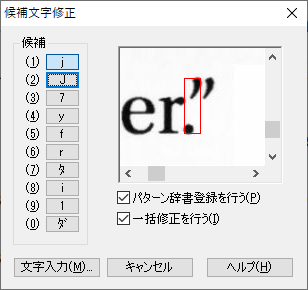
結果として、垂直線で分割できない場合、認識を修正することができません。この場合、キーボードから直接認識結果を修正します。望みは薄そうですが、この方法で修正して、認識辞書の学習につながるのであれば、しつこく修正していれば、いずれ問題なく認識できるようになるかもです。
欧文OCRとして使用する際の問題
OCRアプリケーションを購入すると、ほとんどの製品では、日本語の認識機能と、英語などの欧文の認識機能は、別々の機能になっています。
日本語の文字が、1文字、1文字、四角の枠が用意された原稿用紙に記述することを意識しているのに対して、英語などの欧文の文字は、横に線が描かれた横罫線上に記述することを意識している点です。
つまり、日本語の文字は、一定の横幅を持つのに対して、欧文の文字は、文字ごとに横幅が異なり、前後の文字の組み合わせによっては、重なって表記されます。さらに、欧文では、イタリック体と呼ばれる斜めに記述されたスタイルの文字が存在します。
そのため、文字と文字の隙間が、縦に垂直に存在していることを前提にして認識領域を設定していると、どれだけ認識辞書を育てても文字の誤認識が減少しない結果になります。わかりやすい事例は、小文字のfの前後のi、小文字のiとtが隣接する場合、コンマ.やの後のダブルクォーテーション”(重なる)、yの前の文字、例えばtyなどです。
もう一つの問題は、欧文には、スペースが頻繁に使用されます。日本語OCRでは、スペースが認識されないことがあります。
つまり、英語などの欧文の認識を行う場合は、欧文用に開発されたOCRエンジンを使った方が認識精度が高くなることが期待できます。
「本格読取 5」より、高価価格の製品では、日本語用の認識エンジンと欧文用の認識エンジンの両方を搭載し、手動で切り替えて認識させる方式を取ることが多いです。
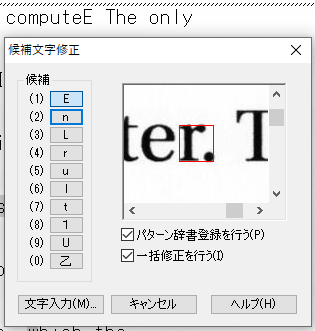
垂直な空白がないことで複数文字が1つの文字と認識される事例
既に、「ig」と「.”」ついて紹介していますが、その他の事例についても紹介します。画像からの文字認識が、難しいことなんとなく想像できると思います。
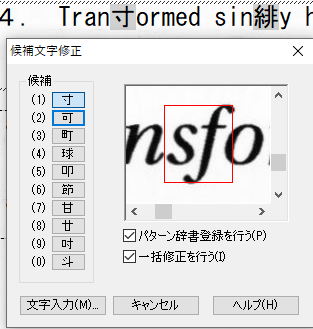
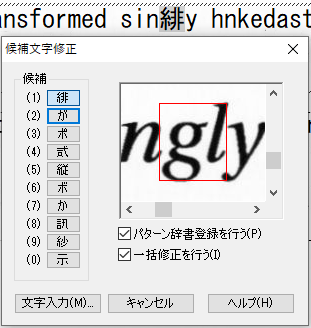
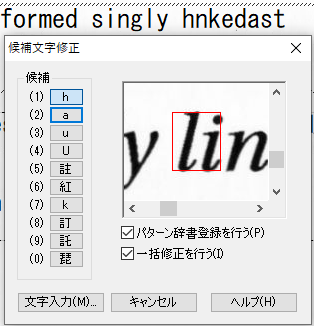
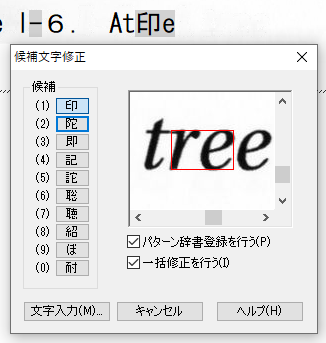
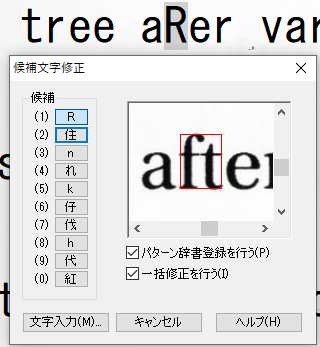
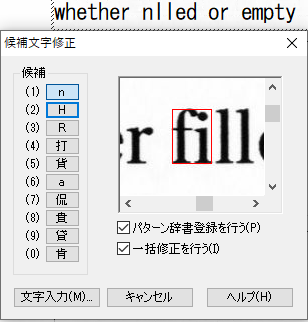
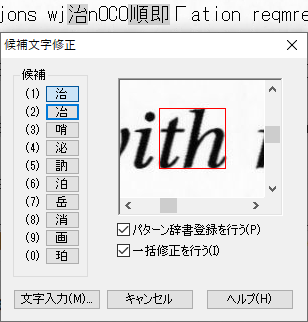
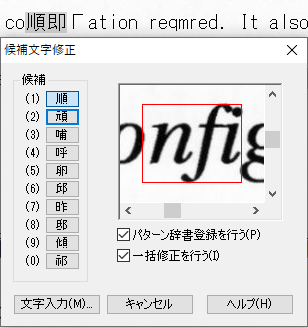

パターン辞書の登録上限
パターン辞書の登録上限数は、10000です。
学習させることで、英文の認識の精度を高める可能性の1つが、崩れました。